Justify My Spending

Last week, I bought a Tesla. Not that Tesla whose founder is said to be exiled to South Africa but NVIDIA's server graphic card line. Not the fancy H100 with 80 GB "golden" VRAM, but a second-hand Tesla T10 "Gaming" GPU. Why I bought this GPU even with another RTX3090Ti on hand? To play games? Could be. I tested playing Tomb Raider with 4K max out on this card it has an average fps around 45 in test bench run. To save powers and avoid heating up my tiny little apartment? Very likely. The RTX3090Ti is like a beast with a 450W TDP. But the answer is that I bought it to build a workstation for my internship at a logistics company where I was asked to transform their current practices.
Why I bought "the" Card
I believe some of you may heard the Tesla T4 as it is the one and the only free tier card that you can use on Google Colab. Well, T10 is the younger brother but more juicy: Same old architecture from 2018; Same old 10nm manufacturing technology; Same old 16GB GDDR6 VRAM. But doubled power consumption to a "warping" 150 TDP, faster memory bandwidth, and slightly more coda cores. It was originally launched for Amazon's cloud gaming services and recently flowed to the second-hand hardware market. The Tesla lineup was bit special as they don't have any display output and no public available driver (on windows). You need a system with iGPU (or another dGPU with display output) in order to use this card. This makes the card not recommended to anyone who simply wants to pick and play. However, for persons like me who "don't mind" building up system till midnight and twisting drivers, it was actually a very professional card with high cost/performance ratio. I bought the modified card (with cooling) at the price little less than 200 dollars. Compared to the GFORCE lineup, the card has a vary generous VRAM (70s) and exceptional bandwidth (60 Tis). This suits well for AI development.
True reasons, I just want to buy something to avoid stress out and balance my mindset.
What I Do with the Card
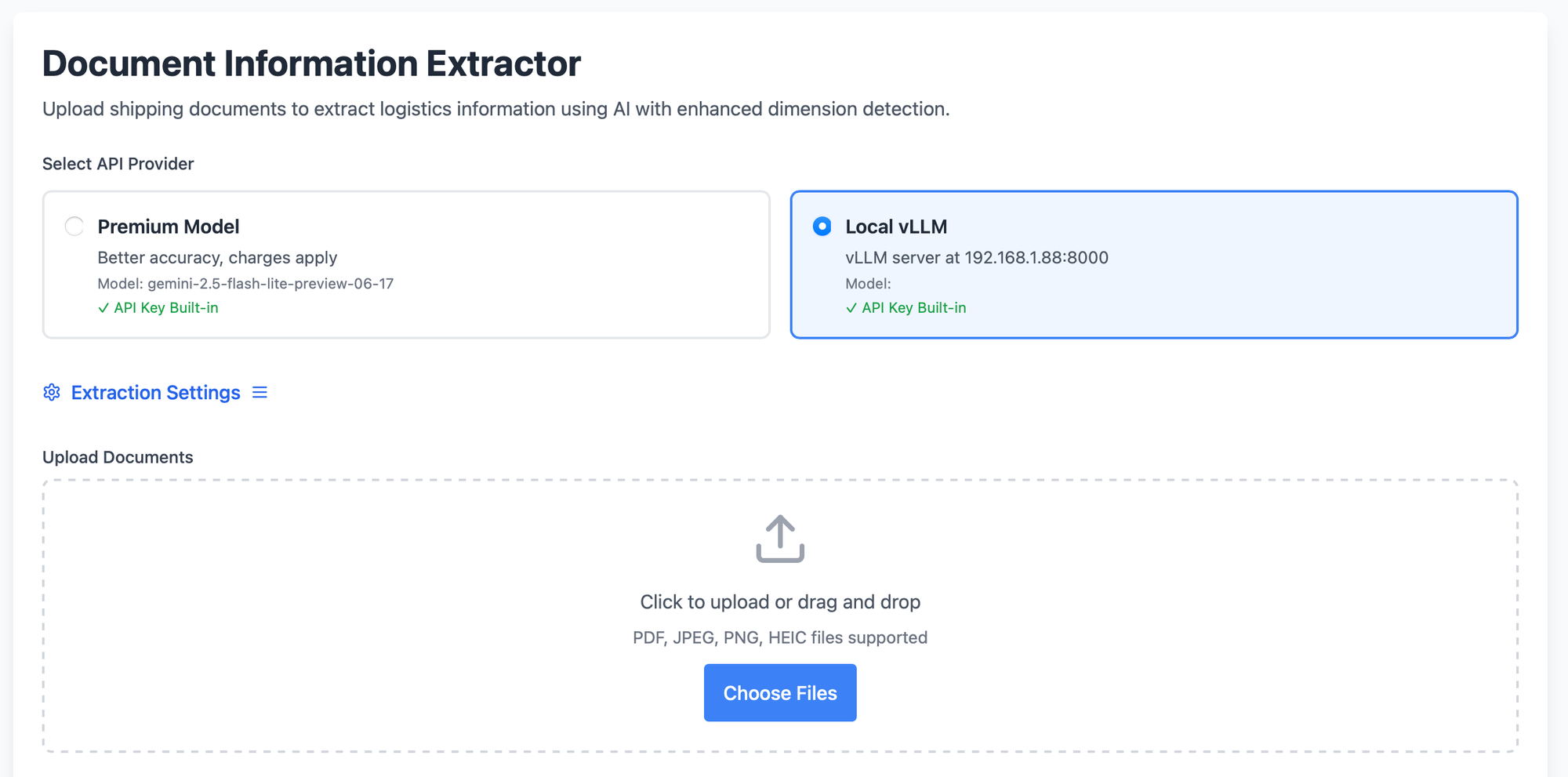
A very important process of many daily operations within the company is to manually input the information from hard-copy documents to an excel spreadsheet. This makes me wonder whether I can automize the process using AI. I first tested the task with many close-sourced models including but not limited to OpenAI's GPT4.1, Google's Gemini 2.5-flash, Anthropic's Claude 3 (Non-flagship model to cost down. Their API cost were all less than 0.5 dollar per 1M tokens). Google actually performs best which can directly handle the image input and extract the information I demand.
However, due to data privacy concerns, I was informed by my supervisor that no document can be uploaded to external server (「公海」as he described). This basically means no state-of-the-art closed-sourced model can be implemented. This is the turning point where I turned to locally-deployable open-source models.
I first tried using one single multi-model (vision model) to perform the same tasks. Gemma3-27B, Mistral Small 3.2 2506 (No Llama 4 families as they are too large to deploy on my local machines). However, they barely can finish the task no need to mention the desirable outcome. I then turned to multi-agents approach to seek solutions.
"nanonets/Nanonets-OCR-s" is a recently released vision model specialized in image to text. The nature of the model was a fine-tuned version of Qwen 2.5VL in image reasoning.
#sample curling script
def ocr_page_with_nanonets_s(image_path, model, processor, max_new_tokens=4096):
prompt = """Extract the text from the above document as if you were reading it naturally. Return the tables in html format. Return the equations in LaTeX representation. If there is an image in the document and image caption is not present, add a small description of the image inside the <img></img> tag; otherwise, add the image caption inside <img></img>. Watermarks should be wrapped in brackets. Ex: <watermark>OFFICIAL COPY</watermark>. Page numbers should be wrapped in brackets. Ex: <page_number>14</page_number> or <page_number>9/22</page_number>. Prefer using ☐ and ☑ for check boxes."""
image = Image.open(image_path)
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": [
{"type": "image", "image": f"file://{image_path}"},
{"type": "text", "text": prompt},
]},
]
Being aware that multiple model will be deployed to complete the process, I first tried a quantized version of the model. This is where I encountered the first issue. As stated in the model repo, vllm was recommended as the engine to run the model. Although VLLM has beta support for GGUF (quantized model format), it does not support model type: QWEN VL. I then tried compile llama.cpp with CUDA support and run the model with:
./bin/llama-server \
-m /home/ross/Nanonets-OCR-s.Q8_0.gguf \
--n-gpu-layers 999
The model can be loaded successfully also seems to entirely lose the vision function. This is where I learned one key ingredient of the vision model falls on a special source: mmporj. As suppose a "mmporj.gguf" file give any gguf model visual functions where to properly load a vision model you need to use:
# I set the LLM service on another machine so should define the service listen from all (0.0.0.0)
./bin/llama-server -m /home/ross/Nanonets-OCR-s.Q8_0.gguf --mmproj /home/ross/Nanonets-OCR-s.mmproj-Q8_0.gguf --port 8000 --n-gpu-layers 37 --host 0.0.0.0
The model now can "see" the image properly. However, it does not mean the model can see "properly". During my several test run, I found the model generate outputs with noticeable defects. Not only does it constantly falls into loop with repeated tokens generated but also omitting a great bunch of information. This makes the model totally unusable so I have no other option but to use the full precision model in fp16 (as the Tesla T10 doesn't support bf16).
Required Libaries
pip show vllm
Name: vllm
Version: 0.9.1
Summary: A high-throughput and memory-efficient inference and serving engine for LLMs
Home-page: https://github.com/vllm-project/vllm
Author: vLLM Team
Author-email:
License-Expression: Apache-2.0
You should notice that due to some conflicts, the latest transformers will send double calling to a module and cause internal conflicts. Hence, you are advised to fall back to previous transformers versions:
pip install transformers<4.53.0
You should also set the environment before serving the model
#set environment
export CUDA_LAUNCH_BLOCKING=1
export TORCH_USE_CUDA_DSA=1
Finally, you can serve the model. This is the config I test that can run the model without OOME.
#serve the model
vllm serve nanonets/Nanonets-OCR-s --dtype float16 --max-model-len 32768 --gpu-memory-utilization 0.9 --limit-mm-per-prompt image=1
Till this point, the first vision agent has been set up ready to serve. This is where we turn to another part of the process by setting up another text processing agent. I select nvidia/Llama-3.1-Nemotron-Nano-4B-v1.1 as it is "Nano" and I have a great impression with its elder brother with larger parameters.
I used a quantized version of the model to preserve the VRAM and there is a tight fit of two model which ate up all 16GB VRAM of my T10.
./llama.cpp/build/bin/llama-server -m nvidia_Llama-3.1-Nemotron-Nano-4B-v1.1-Q8_0.gguf --port 8001 --host 0.0.0.0 --n-gpu-layers 999
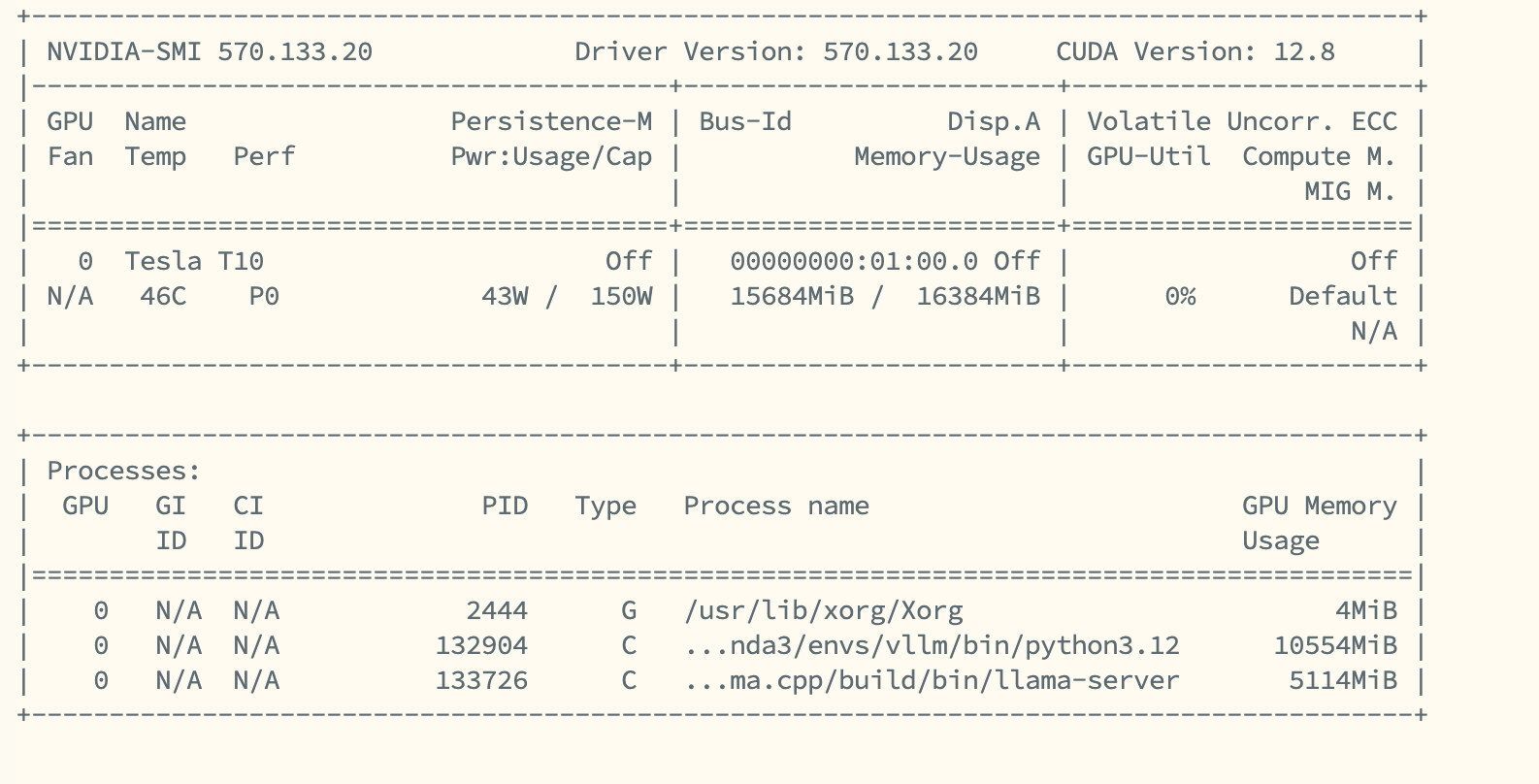
With the first model OCR the file and the second model processing the extracted text, the combination can achieve following effects.
illustrative video