Why Intel! Why!


About six months ago, just after the debut of Intel Battlemage graphics card (the B580), I bought one used (but still in warranty) ARC A770 at the price of $150 USD. The experience of using the card persuaded me to keen on Team Green (Nvidia) and Apple silicon, where I eventually spent over $1,000 on a second hand RTX3090 Ti (of course, founder edition). I tried to resell the machine on carousell but only got one inquiry within the three months listing period. I took the built back to my parent's house (less expensive to store things here). Just before I want to "tear it down" for easier storage, my curiosity drive me to recheck the ipex-llm GitHub repository. Why intel! Why! Why would you continue updating software supports! Why Ross! Why! Why you spent $1,000 on a NVIDIA graphic card!

It all starts with the booming of Generative Artificial Intelligence (GenAI). Back in that time, for a AI layman like me can only use entry level application like "ollama" and "LM Studio". With a single 16GB m2 Pro MacBook, I can only run some generic models at minimum speed. Once, I tried to run a 14B model with longer context than default (4096). The entire system crashed (The only time I witnessed an Apple Silicon Mac crash). To save my Mac's SSD from the torture of SWAP and prevent data loss, I decided to purchase a dedicated GPU.
Green is nice, what about team blue?
When I say choose one GPU to buy, there's not really that much options. Till the moment, there are three major market players: Team Green (NVIDIA), Team Red (AMD), and Team Blue. Naturally, after "playing" for such a long time, you will find that anything can't go without a term called "CUDA". When you google the term, I assure you the logo of NVIDIA will pop up. So as a trial, I placed the order on a second hand RTX3070Ti. I still remember the first time I ran the 7b model on the RTX3070 Ti. As the VRAM got filled by model parameter, the model output was generated at "lightning speed". Back in that time, there was no opensource "Reasoning Model" (TTS model), so the entire eval duration was truly rapid. However, the graphic card can only run 7B model (in 4bit quantization) due to its 8GB VRAM. Anything larger than that would result in CPU cross file and drag eval speed.
To run a larger model, I need a card with more VRAM.
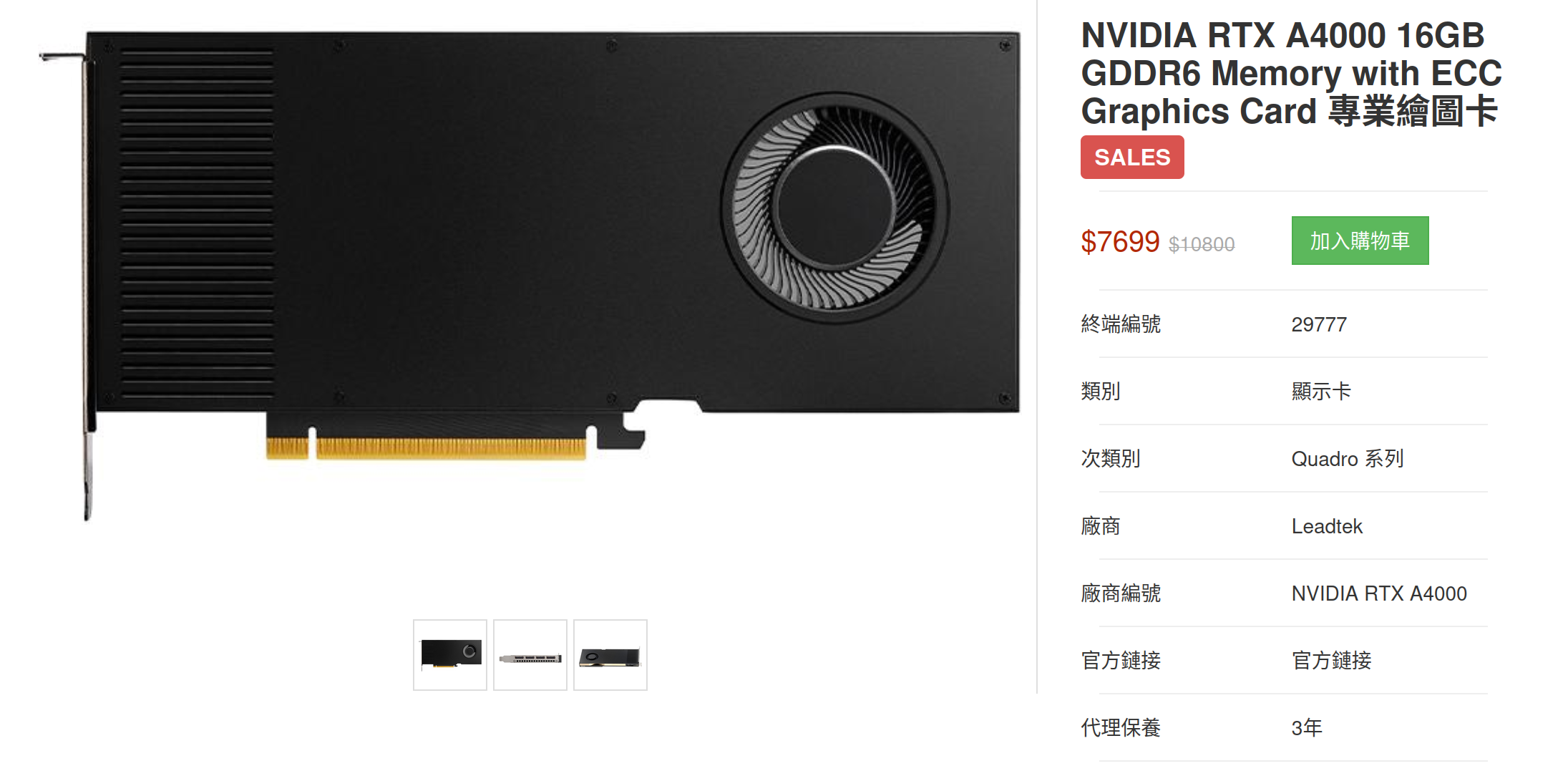
If you ask any AI players what is the characteristic of NVIDIA's GDDR memory, I believe most of them would response you with "expensive". While there is one entry level consumer graphic card "60Ti" with 16GB VRAM, most of them would cost you a fortune. You should be aware that 60Ti is also famous for its bandwidth. Although the 16GB seems to be big, its tiny narrow bandwidth limited its application with severe impact in LLM eval speed.
After realizing the entry barrier for choose team green, I started to look at other alternatives. When I came across the one card, my eyes couldn't move.
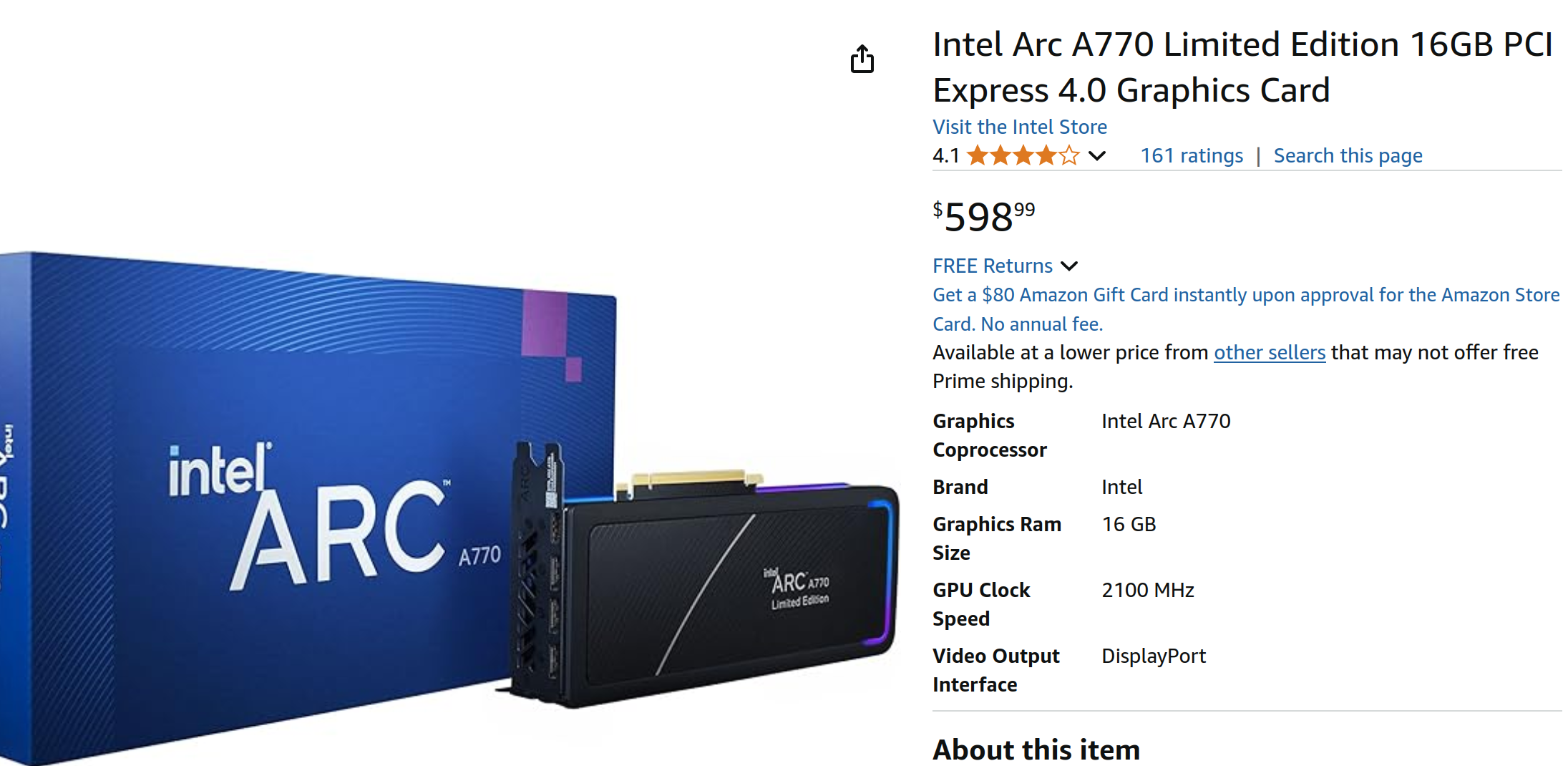
Although with a initial $349 Launching price, the price soon reached a sweet spot of $150 USD. With no patent issues on the paper, it seems a perfect choice for someone who would like to learn AI and also have some demand for video editing (Intel was famous for its video encoding performance). But just like anything else, there will always be a caviar. For Intel GPU, it was its software.
Nice to meet you... ARC?
Although I can buy a new one at the exact same price for the card, I still went for the limited edition which equivalent to NVIDIA's founder edition. When I got the card, I was amazed by how nice the card was built. Painted in pure black, it was surrounded by RGB that will light up after power it up. Personally, I am not a fan of RGB. But, I would still give credits to the design. But here comes the "itchy point": RGB management software only have Windows version and demand addition usb connection. By default, the RGB function is on. So for a person like me who use linux, you have to bear with it (Take it or suck it). It use a 8 + 6 pin pcie power socket. Nothing fancy but just work.

Linux Experience
I first tried Ubuntu on this card. The Linux driver for Intel Graphic Cards was little bit tricky. The newly installed Ubuntu already came with some level of driver for intel. You can already use it for many things but not anything further. To check the GPU status, you can run:
sudo apt install intel-gpu-tools
sudo intel_gpu_topto have a experience similar to NVIDIA's
nvidia-smiHowever, I would say this dashboard was very generic. Compared with NVIDIA, it lacks information related to power consumption, fan speed, and VRAM usage. But still, better than nothing.
You may also noticed a very interesting point, the card was named as "DG2". It remarks the card as the second consumer graphic card developed by Intel. As for "DG1", less people known it as a "dedicated integral GPU". It has a performance similar to Intel's own UHD graphic cards where many NAS or server users adopted it for video trans-coding.
Without further ado, I copy the installation bash command from ollama and try to install it directly.
curl -fsSL https://ollama.com/install.sh | shWhile it can be installed successfully, you will also notice that ollama warns "No GPU was detected. Run on CPU". You will notice this warning many times later in anything related to Pytorch. Till the day, native ollama installation still cannot utilize Intel GPU and you have to use other installation methods. Back in that time, I noticed a repo published on GitHub:
It run ollama and open-webui in docker container which utilize OneAPI. It can run, but still with many limitations. To run everything natively, you have to self-compile and use custom intel solution. Remember I mentioned earlier how Pytorch won't detect the GPU? There is a way to have Pytorch run on Intel GPU which called "torch-ipex". Still, many times, it cannot correctly detect and utilize the GPU I was using. Trying a CNN YOLO model or run Whisper inference? You better prepare for long battle.
Windows Experience
After finding the card may not suit well for "open-box" machine learning experience, I reboot the system into windows. This time, the driver installation process was smooth like butter. The Intel Graphics software allows you to access a bunch of GPU performance metrics which is totally different from Linux experience. It surprised me that unlike ollama which utilize 0% of GPU power, lmstudio this time can use vulkan to utilize the GPU to give something slightly faster than pure CPU inference (still, a lot slower than rtx3070ti or even my MacBook). As windows is not a OS suits for AI, I soon tried other things. Back at its launch time, many people purchase this card as an alternative game gear to RTX3070. I don't play much games on PC so I simply tried GTA IV and Red Dead Redemption II. There is some really wired issues when playing old games like GTA IV where the game locks you from setting graphics to high (locked to 720P low graphics settings so it kind looks like PS3). You have to download some communities mods in order to have a "normal" gaming experience. As for newer games like RDR2, it can run native 4K at 30fps. For a console player like, it was not a big deal and even cooler than my RTX3070Ti. As for its major promotion point: video editing, I will admit its video encoding was terrific. The QSV can compress the video file size while maintaining the fidelity and details which was way better than NVIDIA's NVDEC. However, due to its lower RAW performance, when the timeline was added with great bunch of effects, it cannot ensure full frame playbacks (However, in my workload, even RTX3090Ti cannot ensure full frame playback). In terms of output speed, while RTX3080 can achieve something like 18fps, the arc graphic card can only do 13fps. This performance was similar to apple's M1 max chips.

The card can be a decent GPU for many tasks under Windows especially in comparison with other graphic cards under $150 range. However, you should notice that although the card don't have a very high peak power consumption (300W), it's idle power consumption was quite high. Constantly over 40W.
Continuous Progress
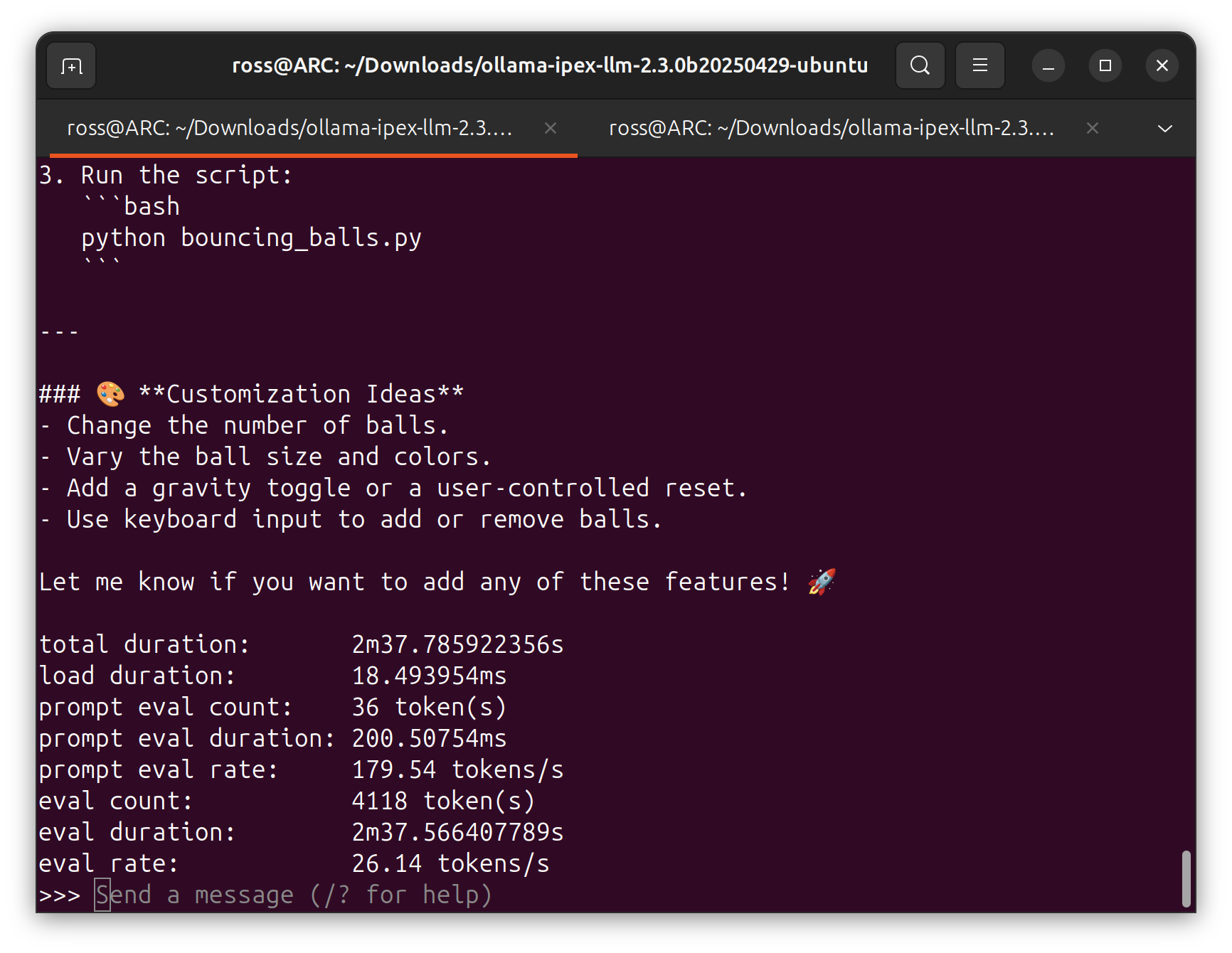
For many people, this might seems quite normal. But I actually yelled out when I this output. While in the past, the
has been constantly updating. It still requires plenty "pre-process" that will likely cause system crash. There is a higher likelihood that the actual script have great discrepancies with its documentation. However, I recently noticed some signs of transition. Indicating their keen promise on improving their software support. Last monthly, tried VLLM on intel GPU. With concerns of corrupting the system again (I don't know how many times I have to reinstall the system due to system corruption or glitch), I tried the service inside the docker container. Out of my expectation, the container was designed pretty neat and organized. I tried to run in-quantized Qwen3 4B (the largest model I can fit in 16GB VRAM). The performance was astonishingly good for a model that big. However, I still encountered context length issue and have to deploy system SWAP. Although it can run, but for most scenario, the maximum context length won't allow the model to have multiple round conversation.
Today, I tried the ollama portable project. It was such a smooth and simple that altered my existing impression to Intel Graphic Cards.
To run the service, you simply first grab the compressed file.
wget https://github.com/ipex-llm/ipex-llm/releases/download/v2.3.0-nightly/ollama-ipex-llm-2.3.0b20250415-ubuntu.tgz
Locate the file and decompress it:
tar -xvf [Downloaded tgz file path]
Then you can start the service backend by:
cd PATH/TO/EXTRACTED/FOLDER
./start-ollama.sh
To use ollama, you will have to reopen another terminal and run
./ollama [ollama command e.g. run qwen3, -h, --verbose, list, ps]
As you can see, the performance was very usable. Given the price of the card, I can imagine having multiple A770 running "genuine" LARGE language model (e.g. Deepseek R1). No need to mention that the coming ARC Pro can make what a significant difference.
So fuck you, NVIDIA!!!